Het Gronings is, net als veel andere dialecten, niet op alle deelgebieden van de linguïstiek even goed bestudeerd. Aan de semantiek – of meer specifiek: de woordenschat – wordt buitenproportioneel veel aandacht geschonken want woordkeus springt in het oog van zowel de leek als de vakman. En er is blijkbaar veel over te zeggen, ook al maakt het, volgens Ede Staal, niet uit of de bakker ‘brood’ of ‘stoet’ bakt. De met name verbale morfologie van het Gronings staat centraal in twee werken van Siemon Reker: zijn proefschrift (1989) en de onvoltooide Groninger Grammatica (1991–1996). Veel minder studies zijn verricht op het gebied van de pragmatiek, de syntaxis alsmede de fonologie en fonetiek. Mijn belangstelling in dit stukje geldt de laatste, de fonetiek. Omdat dit geen bachelorscriptie is, maar slechts een in de kleine uurtjes ontstane blogpost, beloof ik niet meer dan een eerste verkenning van het terrein. De lacunes in de wetenschappelijke kennis kan ik daarmee nauwelijks opvullen, maar misschien vragen opwerpen die later door anderen kunnen worden beantwoord.
Het onderwerp van mijn onderzoekje is de klinkerproductie van één spreekster van het Gronings. Hiervoor heb ik gebruik gemaakt van de opnames op de website van de Liudgerstichten die een aantal passages uit de Groningse vertaling van de Bijbel heeft laten inspreken door vrijwilligers. In totaal komen er een stuk of vijf sprekers langs, maar er was slechts één van wie opnames van toereikende lengte beschikbaar waren. Ik weet het niet zeker (en heb ook niet de moeite gedaan om na te vragen), maar ik denk dat de teksten die ik heb gebruikt, zijn ingesproken door Riemke Bakker, de secretaris van de Stichting Grunneger Toal. Als zij het is, gaat het om een spreekster die in Bedum – in het zuidelijke deel van het Hogeland – woont, maar van wie ik niet weet waar zij is opgegroeid. Het doet er ook niet toe want ik heb toch geen vergelijkingsmateriaal van sprekers uit andere regio’s. Van elke beklemtoonde monoftong (eenklank) die zij in de opnames produceert, heb ik 20 exemplaren geanalyseerd (voor zover er 20 te vinden waren, zie beneden). Ik heb de voorkeur gegeven aan klinkerexemplaren die door een plosief (plofklank) worden voorafgegaan en gevolgd. De grens tussen medeklinker en klinker is in deze gevallen scherper dan bij fricatieven (wrijfklanken) of liquida (vloeiklanken) waardoor de klinker ietwat minder in zijn kwaliteit wordt beïnvloed. Niet bij alle klinkers was het mogelijk om deze strikte selectiecriteria aan te houden, maar ik heb er in ieder geval op gelet om zo min mogelijk klinkers te analyseren die door een /r/ of /l/ worden gevolgd. Wie de uitspraak van de ‘oo’ in ‘rood’ met die in ‘door’ vergelijkt, hoort hoe sterk de invloed van een /r/ aan het einde van de lettergreep op de klinker kan zijn.
Wat betekent ‘geanalyseerd’? Ik heb, met behulp van de gratis software praat, de zogenaamde formanten gemeten van de klinkers die ik uit de opnames had geknipt. Formanten zijn, zou je kunnen zeggen, het DNA van een klinker, dat wat een klinker uniek maakt. Wanneer we spreken, produceren onze stembanden een spectrum van luchttrillingen met veel verschillende frequenties (gemeten in Hertz). Maar de trillingen zijn niet op alle frequenties (trilsnelhelden) even hard. De kleur van elke klank wordt gevormd (vandaar ‘formanten’) door de frequenties waarop de trillingen een bovengemiddelde amplitude hebben of, simpel verwoord, bijzonder hard zijn. In vergelijking met een ‘i’ zijn bij een ‘a’ andere frequenties harder dan gemiddeld. Deze amplitudepieken zijn de formanten en die kunnen, zoals gezegd, worden gemeten met behulp van software zoals praat. De eerste en de tweede formant zijn het meest belangrijk voor de identificatie van een klank. De formanten geven – grofweg, het klopt niet helemaal – de positie van de tong weer bij de klankproductie. De eerste formant (F1) markeert de verticale positie van de tong: Een hogere tongpositie (dichter bij het gehemelte) correspondeert met een lage F1-waarde. De tweede formant (F2) hangt samen met de tongpositie op een horizontale as: Hoe verder achterin de tong zich in de mond bevindt, hoe lager de F2-waarde. De F1/F2-waardes worden meestal afgebeeld in coördinatenstelsels waarvan de x- en y-as elkaar rechtsboven (in plaats van linksonder) snijden – gebaseerd, als het ware, op de mondholte van een persoon die naar links kijkt.
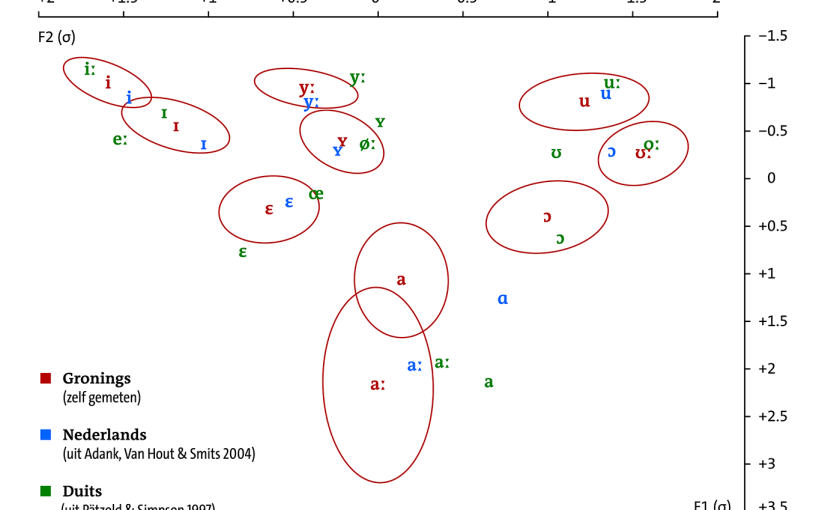
In het diagram hieronder is het volgende te zien: in rood de F1/F2-waardes van elke Groningse monoftong die ik heb gemeten, waarbij de letters (of de fonetische tekens die ik verderop toelicht) voor de gemiddeldes staan en de cirkels telkens één standaarddeviatie rond het gemiddelde aanduiden. Uit eerdere publicaties overgenomen en aan het diagram toegevoegd heb ik de gemiddelde formantenwaardes van alle Nederlandse (in blauw) en Duitse monoftongen (in groen) die in beklemtoonde lettergrepen kunnen voorkomen. De Nederlandse en de Duitse gegevens zijn ook gebaseerd op opnames van vrouwelijke sprekers. De F1/F2-waardes zijn niet in Hertz aangegeven, maar in standaarddeviaties van het gemiddelde van alle klinkers in het systeem. De reden hiervoor is dat ik de gemeten Hertz-waardes volgens de methode van Lobanov heb genormaliseerd. De bedoeling van dergelijke normalisatieprocedures is het om variatie te reduceren die niet in de klinkers zelf ligt, maar door de anatomie van de sprekers wordt veroorzaakt. De methode van Lobanov kwam in een aantal onderzoekingen als (een van) de beste uit de bus en lijkt me daarom goed genoeg voor deze exploratieve studie, ook al heeft de methode, net als elke andere, niet alleen voordelen. Hoe het ook zij: Dit zijn de resultaten.
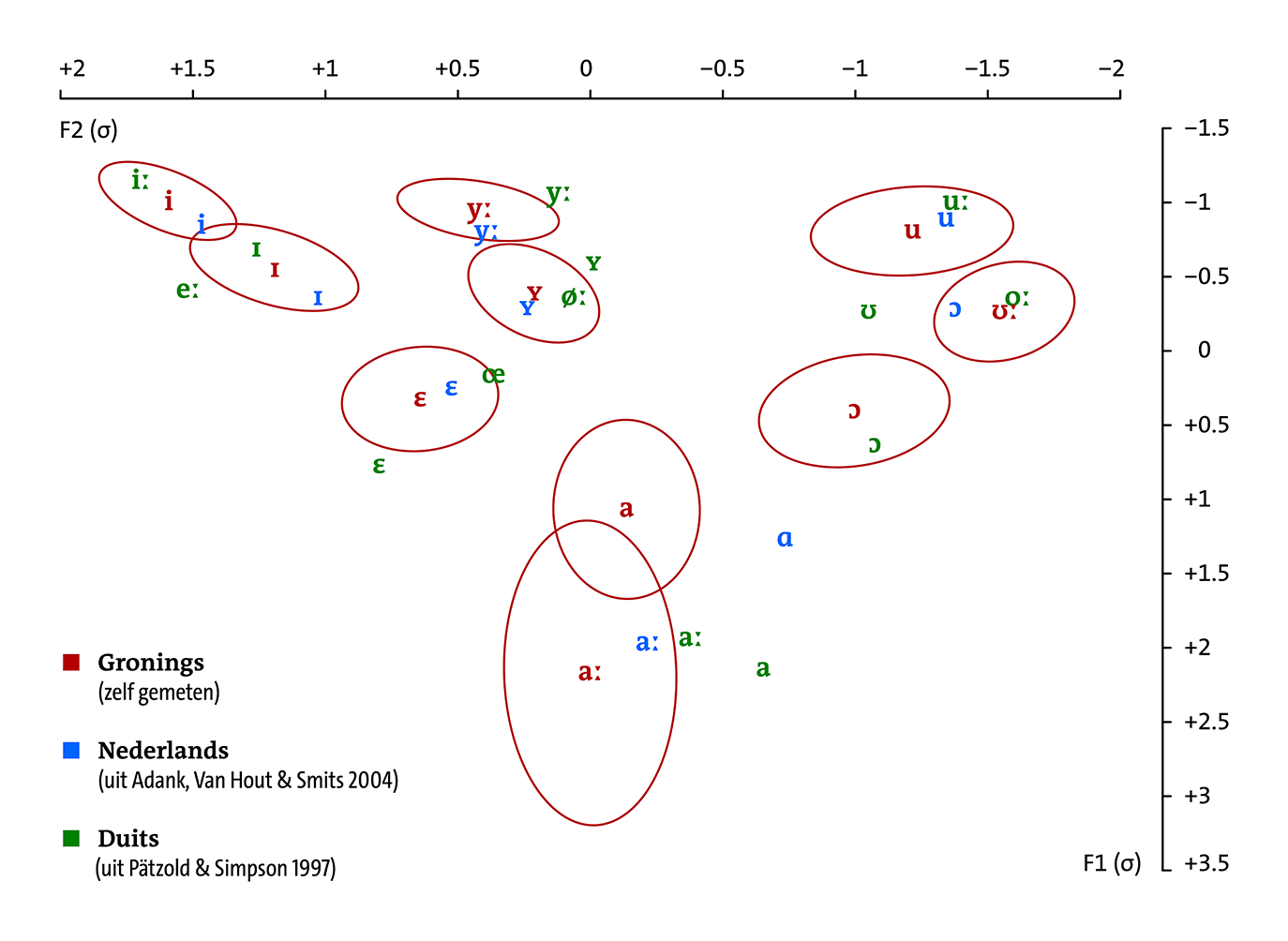
Laten we de klanken de een naar de ander bekijken. We beginnen linksboven bij de [i] en gaan – zoals men in Vlaanderen zegt – ‘in wijzerzin’, rechtsom dus, verder. [i] is de klank in Gronings/Nederlands/Duits ‘wie’ (in het Duits lang, in de twee andere variëteiten kort), [ɪ] is de klank in Gronings/Duits ‘mit’ en Nederlands ‘pit’. In allebei de gevallen zijn verschillen tussen de drie variëteiten niet erg groot. De Groningse klank lijkt telkens tussen de Duitse en de Nederlandse klank in te zitten. In de buurt van de [i] en de [ɪ] heeft het Duits nog de [eː] van ‘Beet’. De Groningse en Nederlandse tegenhangers van deze klank worden als tweeklank, [eɪ̯] namelijk, gesproken en ontbreken in het diagram, aangezien ik tweeklanken – om een aantal praktische redenen – hier niet behandel. Als we verder kijken naar de [y] van Gronings/Nederlands ‘minuut’ en Duits ‘Mühe’ (in het Duits lang, in de twee andere variëteiten kort) en de [ʏ] van Gronings/Nederlands ‘lust’ en Duits ‘Hütte’, zien we een enigszins andere verdeling dan bij de ‘i’-klanken: De Groningse en de Nederlandse klanken klitten telkens bij elkaar terwijl de Duitse klanken vooral een lagere F2, maar ook een iets lagere F1 lijken te hebben. Let wel dat in dit gebied weer twee klanken ontbreken, namelijk de Groningse en de Nederlandse ‘eu’ die telkens als de diftong [øʏ̯] worden gerealiseerd en daarmee ook buiten het bereik van deze verkenning vallen. De Duitse [øː] staat in ieder geval erg dicht bij de Duitse (en ook de Nederlandse en Groningse) [ʏ]. Het zou kunnen dat de differentiëring van deze twee klanken vooral gebaseerd is op lengte. We kijken verder naar de [u] van Gronings/Nederlands ‘toen’ en Duits ‘Mut’ (ook deze lang in het Duits, maar kort in het Nederlands en Gronings) en zien wederom weinig verschillen tussen de talen. De Groningse [u] lijkt wat sterker gecentraliseerd dan de Duitse en Nederlandse, maar de afstanden zijn klein. Interessanter is het gebied van de ‘o’-achtige klanken daaronder: [ɔ] is de klank van Gronings/Nederlands ‘pot’ en Duits ‘Pott’, [ʊː] is de karakteristieke lange ‘oa’-klank van het Groningse ‘loat’ (een lastige klank voor Nederlanders), [ʊ] komt in het Duitse ‘Butter’ voor (eveneens een lastige klank voor Nederlanders) en [oː] in het Duitse ‘Boot’. De Groningse en Nederlandse tegenhangers van deze laatste klank – de gediftongeerde [oʊ̯] van ‘boot’ – missen we helaas. Twee dingen vallen op: Ten eerste heeft de Nederlandse [ɔ] behoorlijk lagere F1- en F2-waardes dan de Groningse en de Duitse klanken die sterk op elkaar lijken. Dat schijnt op het eerste gezicht misschien gek, maar zou – als uitgebreider onderzoek deze tendentie bevestigd – verklaard kunnen worden door het feit dat het Nederlands, anders dan de twee andere variëteiten, in dit gebied slechts één korte klank, namelijk juist de [ɔ], heeft. In het Duits daarentegen heeft de [ɔ] minder speelruimte omdat er ook nog de [ʊ] zit. En ook het Gronings heeft een korte [ʊ], namelijk de soms ‘ó’ geschreven klank in woorden als ‘vot’ of ‘pótje’ – dat laatste in de betekenis ‘baby’, in contrast met ‘pòtje’ (een kleine pot) wat met een [ɔ] wordt gesproken. Jammer genoeg heb ik niet voldoende eenduidige voorbeelden van de [ʊ]-klank in de opnames kunnen vinden zodat pas verder onderzoek zal uitwijzen waar deze klank in het Groningse klinkersysteem geplaatst kan worden. Ten tweede valt op dat de Groningse lange [ʊː] nagenoeg identiek lijkt te zijn met de Duitse [oː]. Desondanks zou het verstandig kunnen zijn om de Groningse klank [ʊː] te blijven transcriberen. In minder nauwkeurige of fonologische transcripties wordt namelijk de diftongische [oʊ̯] soms als [oː] weergegeven wat tot verwarring zou kunnen lijden. De klank waarbij de drie variëteiten het minst op elkaar lijken, is de korte [a] of [ɑ] van Gronings/Nederlands ‘had’ en Duits ‘hat’: De Duitse en de Nederlandse klank worden met even lage F2-waardes geproduceerd waarbij de F1-waarde van de Nederlandse klank beduidend lager ligt dan die van de Duitse. De F1-waarde van de Nederlandse [ɑ] komt overeen met die van de Groningse [a] die echter een hogere F2-waarde heeft dan de andere korte ‘a’-klanken. De Groningse [a] lijkt misschien nog het meest op de Duitse [ɐ] die in het diagram ontbreekt omdat hij in beklemtoonde lettergrepen niet voorkomt, maar slechts als realisatie van ‘-er’ in woorden als ‘Vater’. Bij de [aː] van Gronings ‘laank’, Nederlands ‘praat’ en Duits ‘Rat’ liggen de drie variëteiten weer dichter bij elkaar: De F1-waardes zijn min of meer hetzelfde. De Duitse klank heeft de laagste F2-waarde, de Groningse de hoogste. Ik ben benieuwd of toekomstig onderzoek kan bevestigen dat de Groningse en de Nederlandse [aː] redelijk dicht bij elkaar liggen. Het laatste trio klanken in het diagram is de [ɛ] van Gronings/Nederlands ‘pet’ en Duits ‘Bett’. Net als bij de ‘u(u)’-klanken is ook ditmaal weer de Duitse klank het buitenbeentje met hogere F1- en F2-waardes terwijl de Groningse en de Nederlandse klank sterk op elkaar lijken. De reden waarom de Duitse korte ‘e’ anders wordt gerealiseerd, kan ik niet meteen aanwijzen.
Wat is de conclusie uit deze eerste verkenning? Allereerst wil ik er nog eens op wijzen dat ik helaas niet het hele klinkersysteem en nog niet eens alle monoftongen van het Gronings heb kunnen analyseren. De omissie van de ‘ó’, uitgesproken als [ʊ], heb ik al vermeld. Verder ontbreken de ‘è’ van ‘wèst’ die als [ɛː] of als centrerende diftong [ɛə̯] wordt gerealiseerd, de nasale ‘ì’ of ‘è’ van ‘ìnd/ènd’ die waarschijnlijk [ɪ̃ː] luidt, de korte en de lange ‘ö’ van ‘röt’ en ‘börg’, [œ(ː)] dus, alsmede – zoals gezegd – alle diftongen en, desgevallend, hun monoftongische realisaties. Het feit dat de genoemde monoftongen in de opnames nog geen 20 keer voorkwamen, geeft al blijk van de marginale positie en lage frequentie van deze klanken. Op de basis van de klanken die ik wel heb geanalyseerd, kunnen in ieder geval een aantal vragen worden geformuleerd waar hopelijk ooit uitgebreider onderzoek antwoorden op kan geven:
- Hoe consistent worden de [ɔ] en de [ʊ] in het Gronings nog uit elkaar gehouden? Wanneer ik naar sprekers van het Gronings luister, heb ik vaak moeite om te horen welke van de twee klanken wordt gebruikt. Dat zou aan mij kunnen liggen. Of zou het ook kunnen dat de traditionele verdeling van de klanken aan stabiliteit heeft ingeboet? Zijn de twee klanken misschien naar elkaar toegegroeid? De [ʊː] en de [ɔ] lijken in mijn metingen nauwelijks op elkaar, maar natuurlijk missen we, naaste de ‘ó’, ook de ‘oo’ om het plaatje compleet te maken.
- Er wordt vaak beweerd dat de Groningse korte ‘i’ niet op die van buurtalen als het Nederlands of het Duits lijkt. De Groningse [ɪ] zou sterker gecentraliseerd zijn of een hogere F1-waarde hebben – tenminste maak ik dat op uit de impressionistische beschrijvingen van moedertaalsprekers. Uit mijn metingen blijkt hier niets van. Het is juist de Nederlandse [ɪ] die het meest gecentraliseerd is en de hoogste F1-waarde heeft. Heeft dat met de klankomgeving te maken? Klinkt de Groningse [ɪ] slechts anders wanneer, bijvoorbeeld, een nasale klank volgt? Alle [ɪ]-exemplaren die ik heb geanalyseerd, waren omgeven door plof- of wrijfklanken. Misschien is de [ɪ] in ‘zingen’ (die in mijn steekproef ontbreekt) een heel andere dan die in ‘mit’.
- Hoe komt het nou eigenlijk dat de lange ‘aa’ van het Nederlands door moedertaalsprekers van het Gronings vaak als geheel frontale [a] of zelfs [æ] wordt gerealiseerd? Ik hoorde ooit dat de reden hiervoor in het feit zou kunnen liggen dat de Groningse [aː] met een lagere F2-waarde wordt gesproken dan de Nederlandse [aː]. In hun poging de hogere F2-waarde van het Nederlands te bereiken, zouden sprekers van het Gronings dan misschien doorschieten en een klank met een veel te hoge F2-waarde produceren. Blijkens mijn metingen is de F2-waarde van de Groningse [aː] echter hoger, niet lager, dan die van de Nederlandse klank, maar ook weer niet zo hoog dat de Groningse [aː] voor moedertaalsprekers van het Nederlands als [æ] zou kunnen klinken. Zouden dezelfde waardes ook uit grondiger onderzoek naar voren komen en, zo ja, wat is er dan de verklaring voor dat Groningers in het Nederlands een klank produceren die noch in deze taal noch in hun eigen moedertaal voorkomt?
- Zou je dezelfde formantenwaardes vinden in spontane spraak? De analyse van voorgelezen teksten is slechts een noodoplossing bij gebrek aan andere makkelijk beschikbare opnames. Het valt op dat de spreekster van de gebruikte opnames ervaring heeft met het omzetten van geschreven Gronings in enigszins natuurlijke spraak. Veel andere moedertaalsprekers van het Gronings raken door de ongewone spelling in de war en gaan bij het hardop lezen van teksten opeens klanken heel anders produceren dan ze dat spontaan zouden doen. Ik zou daarom aanbevelen om een driestapsprocedure te volgen bij de elicitatie (het ‘uitlokken’, als het ware) van gegevens voor een grondigere fonetische analyse: Allereerst zou – onder een of ander sociologisch voorwendsel – een uitgebreid spontaan gesprek moeten worden opgenomen met elke spreker. Daarna zou een taalspelletje kunnen volgen waarbij eveneens niet de uitspraak, maar iets anders op de voorgrond zou moeten worden geplaatst. Je zou iets met woordenschat kunnen doen of de sprekers vragen om zinnen van de tegenwoordige tijd in de verleden tijd om te zetten, als ze maar niet doorhebben dat het over fonetiek gaat. Pas aan het eind zou je je informanten kunnen vragen om lijstjes met korte zinnetjes of afzonderlijke woorden voor te lezen. Ik zou deze stap niet overslaan om te waarborgen dat je van elke klank zeker weten voldoende exemplaren hebt. Bij de analyses zou je dan hoofdzakelijk uit de spontane gesprekken kunnen putten, deze gegevens waar nodig met een aantal exemplaren uit het tweede deel aanvullen en slechts in uitzonderlijke gevallen teruggrijpen op de woordenlijstjes van het derde deel.
Dit allemaal te analyseren – en dan niet voor één spreker, maar voor telkens 20 uit een aantal verschillende plaatsen en misschien zelfs uit twee of drie verschillende leeftijdscategorieën of zo – is zonder twijfel klotewerk, maar het was, als je het aan mij vraagt, stief de muite weerd.
Pingback: Celebrating Dialect Month: 31 songs in small Germanic varieties | Isoglosse.